Threads (zu deutsch "Fäden") ermöglichen die gleichzeitige Ausführung von mehreren Programmpfaden innerhalb des Adreßraums eines Prozesses. Threads werden nicht nur in der parallelen Programmierung sondern vielfach auch in Client-Server Anwendungen eingesetzt. Auch unter Linux sind Thread-Pakete für C und C++ verfügbar.Der erste Teil dieses Artikels beschreibt die Grundlagen der Thread-Programmierung, gibt einen kurzen Überblick über den POSIX Thread Standard, und verweist auf Thread-Pakete, die unter Linux verfügbar sind. Der zweite Teil wird RT++ beschreiben, eine C++ Klassenbibliothek für die parallele Programmierung auf Multiprozessor-Systemen, Workstations und Linux-PCs.
Bevor wir näher auf die Thread-Programmierung eingehen, müssen wir uns erst einmal mit den entsprechenden Betriebssystem-Grundlagen vertraut machen.
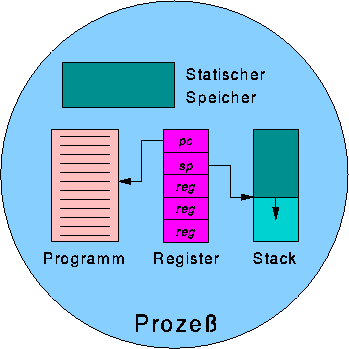
Ein Prozeß besteht dabei aus den folgenden Komponenten:
malloc bzw. dem C++ Operator
new erzeugt werden.
In diesem traditionellen Modell ist mit jedem Prozeß ein einziger sequentieller Kontrollfluß verbunden, der durch den Inhalt des Programmzeigers und den in Registern, Stack und statischem Speicher enthaltenen Werten bestimmt wird. In einem Multi-Prozessor System können verschiedene Prozessoren zu gleicher Zeit verschiedene Prozesse ausführen; Prozesse stellen damit die natürlichen Einheiten der Parallelisierung dar. Aber auch in Systemen mit nur einem Prozessor werden durch Umschalten (context switch) von einem Prozeß zum nächsten alle Prozesse "quasi-parallel" abgearbeitet. Bei jedem Umschalten werden dabei die Register-Inhalte des alten Prozesses auf dem Stack gespeichert und die Register mit den entsprechenden Werten vom Stack des neuen Prozesses initialisiert.

Ein Prozeß enthält einen oder mehrere Threads, von denen jeder über einen eigenen Programmzeiger, Registersatz und Stack verfügt. Threads verhalten sich damit in Bezug auf ihre Ausführung wie Prozesse, d.h. sie werden vom Betriebssystem unabhängig voneinander (und auf einem Multiprozessor-System echt parallel) ausgeführt. Im Gegensatz zu Prozessen operieren die Threads eines Prozesses aber im gleichen Adreßraum; sie teilen sich also den statischen Speicher und greifen damit auf die gleichen globalen Variablen zu. In gleicher Art und Weise teilen sich threads alle anderen Prozeß-spezifischen Informationen wie geöffnete Dateien, Signale, Funktionen zur Signal-Behandlung, etc.
Während verschiedene Prozesse durch Speicherschutz-Mechanismen voreinander abgeschottet sind und so der Absturz eines Prozesses einen anderen Prozeß nicht betrifft, sind die Threads eines Prozesses in keiner Weise voreinander geschützt. Dafür aber können sie über den gemeinsamen Speicher sehr effizient (ohne den Umweg über das Betriebssystem) miteinander kommunizieren und so kooperieren. Da auch die Erzeugung von Threads im allgemeinen sehr effizient ist, eignen sich Threads daher hervorragend für die fein-körnige Parallelisierung von Anwendungen, wo jede Thread nur einen sehr geringen Teil der gesamten Arbeit erfüllt.
Threads werden daher auch manchmal als leicht-gewichtige Prozesse (LWP, light-weight processes) bezeichnet.
Ein gutes Beispiel dafür sind Client-Server Anwendungen, bei denen ein Server-Prozeß auf die Anforderungen eines oder mehrerer Klienten reagieren muß. Für einen Datei- oder Datenbank-Server kann es sich dabei notwendig sein, laufend einen Strom von Anfragen von Hunderten von Klienten zu beantworten.
Der klassische sequentielle Rahmen für einen solchen Server sieht folgendermaßen aus:
server()
{
while (1)
{
r = receive_request();
a = process_request(r);
answer_request(r, a);
}
}
Diese Lösung besitzt allerdings den Nachteil, daß eine einzige komplexe
Anfrage den Server auf längere Zeit blockieren kann und damit die Beantwortung
aller später eingelangten Anfragen ungebührlich lange verzögert wird.
Eine entsprechende Lösung unter dem Einsatz von Threads würde dagegen den Server folgendermaßen realisieren:
dispatcher()
{
while (1)
{
r = receive_request();
start_thread(worker, r);
}
}
worker(r)
{
a = process_request(r);
answer_request(r, a);
}
Der Server wird dabei zum Dispatcher (Zuteiler), der zur Bearbeitung
jeder Anforderung eine neue Thread erzeugt. Der Server ist damit nur so lange
blockiert, wie zum Empfang der Anforderung und zur Erzeugung der Thread
notwendig sind.
Diese Lösung hat allerdings den Nachteil, daß nach Beantwortung einer Anfrage die jeweilige Thread terminiert und für spätere Anfragen Threads neu erzeugt werden müssen. Diese immerwährende Folge von Erzeugen neuer Threads und Termination alter Threads wird durch folgende Struktur vermieden:
R requests[N];
dispatcher()
{
T threads[N];
create_threads(threads);
while (1)
{
r = receive_request();
p = idle_thread();
requests[p] = r;
wake_thread(threads[p]);
}
}
thread(p)
{
while (1)
{
sleep_tread();
a = process_request(requests[p]);
answer_request(r, a);
}
}
Der Dispatcher erzeugt zu Beginn einen Pool von Threads, von denen jede zur
Bearbeitung einer Vielzahl von Anforderungen herangezogen werden kann. Sobald
eine Thread eine Anforderung erledigt hat, legt sie sich schlafen und wird vom
Dispatcher aufgeweckt, wenn eine neue Anforderung zur Bearbeitung ansteht. Die
Kommunikation zwischen Dispatcher und Thread erfolgt dabei über eine globales
Feld requests, in das der Dispatcher die jeweils zu beantwortende
Anforderung schreibt und die von den Threads gelesen wird.
Die wesentlichste Bestrebung zur Standardisierung hat das IEEE mit dem POSIX-Standard P1003.1c "Portable Operating System Interface for Computer Environments, Threads Extensions" unternommen (als POSIX Threads oder Pthreads bekannt). Trotz der 1995 erfolgten Verabschiedung dieses Standards ist nicht zu erwarten, daß alle Hersteller auf ihre eigenen Programmier-Schnittstellen mit ihren spezifischen Eigenheiten und Erweiterungen verzichten. Zumindest als Alternative aber bieten die meisten eine weitgehend POSIX-kompatible Schnittstelle auf ihre Implementierungen an. Beispielsweise unterstützt Sun Microsystems neben den eigenen Solaris Threads auch POSIX Threads; die Gemeinsamkeiten und Unterschiede zwischen beiden Schnittstellen sind in der "Threads Page" [2] dokumentiert.
Im folgendes zeigen wir ein kleines Beispiel, das die wesentlichsten Punkte des POSIX Thread Modells beschreibt:
#include <pthread.h> /* Posix 1003.1c threads */
...
pthread_mutex_t mutex; /* Wechselseitiger Ausschluss */
pthread_cond_t cond; /* Bedingungsvariable */
pthread_key_t key; /* Thread-specifischer Datenschluessel */
int counter; /* Thread-Zaehler */
void print(void)
{
char *string = (char*)pthread_getspecific(key);
printf("%s", string);
}
void *thread(void *arg)
{
int number; /* 0 = hello, 1 = world */
pthread_mutex_lock(&mutex);
number = counter; counter++;
pthread_mutex_unlock(&mutex);
pthread_setspecific(key, ((char**)arg)[number]);
if (number)
{
print();
pthread_cond_signal(&cond);
}
else
{
pthread_cond_wait(&cond);
print();
}
return(0);
}
int main()
{
char* strings[] = {"hello ", "world\n"};
pthread_t thread1. thread2;
pthread_init();
mutex = PTHREAD_MUTEX_INITIALIZER;
cond = PTHREAD_COND_INITIALIZER;
pthread_key_create(&key, NULL);
number = 0;
pthread_create(&thread1, NULL, thread, strings);
pthread_create(&thread2, NULL, thread, strings);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return(0);
}
Dieses Programm druckt "hello world" (zugegebenermaßen auf etwas
eigentümliche Weise) aus. Dazu verwendet es zwei Threads, die mittels einer
globalen counter Variable bestimmen, wer für das "hello" und wer für
das "world" zuständig ist. Die Ursprungs-Thread wartet auf die Termination
der beiden Threads und beendet dann das Programm.
In diesem Beispiel werden bereits eine Vielzahl wesentlicher Konzepte der Thread Programmierung und des POSIX Thread Standards veranschaulicht:
erzeugt eine neue thread, die fun(arg) ausführt. attribute istpthread_create(thread, attribute, fun, arg)
NULL oder legt verschiedene Thread
Attribute (wie das verwendete Scheduling Verfahren) fest.
wartet auf die Termination von thread. status istpthread_join(thread, status)
NULL oder
liefert zusätzliche Information über die terminierte Thread.
ist ein Mutex (mutual exclusion, wechselseitiger Ausschluß). Ein Mutex kann zum Schutz einer kritischer Region eingesetzt werden, die zu jedem Zeitpunkt nur von einer Thread betreten werden darf. Durch die Operationenpthread_mutex_t mutex;
wird der Mutex gesperrt bzw. freigegeben. In obigem Beispiel dient der Mutex zum Schutz der globalen Variable counter, die von beiden Threads gelesen und um eins erhöht wird. Die Thread, die dabei schneller zum Zug kommt, druckt das "hello", die langsamere Thread das "world".pthread_mutex_lock(&mutex); pthread_mutex_unlock(&mutex);
wird zur Synchronisation der beiden Threads untereinander eingesetzt. Dabei führt die "world" Thread die Operationpthread_cond_t cond;
die die Thread so lange blockiert bis die "hello" Thread mittelspthread_cond_wait(cond);
die entsprechende Bedingung gesetzt hat. Damit ist sichergestellt, daß das "world" erst nach dem "hello" gedruckt wird.pthread_cond_signal(cond);
wird ein Schlüssel key für thread-spezifische Daten definiert (wobei destructorpthread_key_create(key, destructor);
NULL oder eine benutzer-definierte
Destruktor-Funktion ist) . Jede Thread kann nun mittels
einen Wert val an key binden und mittelspthread_setspecific(key, val);
den an key gebundenen Wert lesen. Dieser Wert ist damit global innerhalb aller Funktionen, die innerhalb der gleichen Thread ausgeführt werden (während statisch deklarierte Variablen global für alle Threads sind)! In obigem Beispiel wird mittels einer thread-spezifischen Variable festgelegt, welche Zeichenkette diepthread_getspecific(key)
print
Funktion ausdrucken soll.
Ansonsten aber ist die Unterstützung des Betriebssystems nicht notwendig, um Threads zu implementieren. Tatsächlich bietet es eine Reihe von Vorteilen, Threads auf der Benutzer-Ebene, d.h. ohne Wissen und Unterstützung des Betriebssystems, zu realisieren: