

Huffman Encoding
Table of Contents
1 Huffman Encoding
Huffman encoding is a method of compressing strings. The key idea is to replace each character in the string by a sequence of bits in such a way that characters occurring more frequently have a shorter bit representation than characters occurring less frequently. This usually saves space compared to an encoding where all characters are represented by bit sequences of equal length (as, for example, in the standard ASCII encoding). For this, we have to compute the frequencies of all characters and then to organise that information in a binary tree. The tree can then be used for both the encoding and the decoding of the input string. See Wikipedia for a detailed description.
We are going to derive a (simplistic) Maple implementation of the functions needed to encode and to decode strings using Huffman's method. It will provide an example of how custom data structures (in this case binary trees) can be represented and used in Maple.
2 The Huffman Tree
We start with the computation of the frequency list. Maple does provide the CharacterFrequencies function in the StringTools package for this. We can test that it works by applying it to the example sentence from the Wikipedia article on Huffman encoding.
wikiExample := "this is an example of a huffman tree":
StringTools:-CharacterFrequencies(wikiExample);
" " = 7, "a" = 4, "e" = 4, "f" = 3, "h" = 2, "i" = 2, "l" = 1, "m" = 2, "n" = 2, "o" = 1, "p" = 1, "r" = 1, "s" = 2, "t" = 2, "u" = 1, "x" = 1
The next step is to turn the frequency sequence into a Huffman
tree. Although it is possible to represent trees in Maple by simply
using nested lists, we will implement a more advanced method. This
will be both more readable and less error-prone. The idea is to
introduce data types for nodes and leaves of our trees. We will use an
expression of the form Leaf(d) to represent a leaf with data d and
we will use Node(l,r) for representing a node with left subtree l
and right subtree r.
Maple does not have a formal data type declaration and in fact, we could use the expressions just without further preparations. However, we decide to enable type checking for our trees. This way, we can later easily check whether something is a leaf or node. Also, we can use the types in the argument lists of procedures in order to guard ourselves against wrong input.
`type/Leaf` := proc(expr) op(0,expr) = Leaf and nops(expr) = 1 end proc: `type/Node` := proc(expr) op(0,expr) = Node and nops(expr) = 2 end proc: `type/Tree` := Or(Leaf, Node):
A more complete check for nodes would try to verify that the two arguments (that is, the left and right subtree) are indeed again trees. For this implementation, though, this will not be necessary.
We can check that type checking actually works.
type(4, Leaf), type(Leaf(3), Leaf), type(Leaf(3,2), Leaf);
false, true, false
We also implement a couple of convenience functions for accessing the data inside our trees. Again, these functions are not strictly necessary; but they provide a cleaner interface to the trees. Using op directly bears the danger of messing up the places. Also, if we later decide to change the representation of our trees, we would only need to change these few functions instead of hunting for occurrences of op in the entire code base.
leafData := proc(leaf :: Leaf) op(1,leaf) end proc: leftSubTree := proc(node :: Node) op(1,node) end proc: rightSubTree := proc(node :: Node) op(2,node) end proc:
For a more serious tree implementation one should of course create a proper module. However, for our example the simpler approach will be fine.
We are now prepared to implement the creation of Huffman trees from a given string. The following description of the algorithm is taken from Wikipedia:
- Create a leaf node for each symbol and add it to a priority queue.
- While there is more than one node in the queue:
- Remove the two nodes of highest priority (lowest probability) from the queue
- Create a new internal node with these two nodes as children and with probability equal to the sum of the two nodes' probabilities.
- Add the new node to the queue.
- The remaining node is the root node and the tree is complete.
Note that this algorithm ensures that characters with low frequencies are deeper inside the tree because they are selected earlier in the algorithm. Characters with high frequencies on the other hand will end up closer to the top.
The translation into Maple is mostly straight-forward. First, we
explode the string into its individual characters. Then we compute
their frequencies and create a queue with entries of the form
[Leaf(c),f] where c is a character and f is its frequency. Next,
we sort the queue with respect to the second entries (that is, the
frequencies). This all corresponds to the first item in the
description of the algorithm. For the second item, we remove the first
two entries from the queue (that is, those with the lowest
frequencies) and create a new node from them. We include the node into
the queue and sort again by frequencies. This continues until there is
only one entry left in the queue. We return the tree part of this
entry.
HuffmanTree := proc(string) local explode, queue, a, b: explode := convert(string, list): queue := [StringTools:-CharacterFrequencies(string)]: queue := map(v -> [Leaf(lhs(v)), rhs(v)], queue): queue := sort(queue, key=(x -> x[2])): while numelems(queue) >= 2 do a := queue[1]: b := queue[2]: queue := [ [Node(a[1],b[1]), a[2]+b[2]], op(queue[3..]) ]: queue := sort(queue, key=(x -> x[2])): end do: return queue[1][1] end proc:
We apply the function to the example sentence. (We manually reformatted it in order to make it more readable).
tree := HuffmanTree(wikiExample);
Node(
Node(
Node(
Leaf("a"),
Leaf("e")),
Node(
Node(
Node(
Leaf("l"),
Leaf("o")),
Leaf("h")),
Node(
Node(
Leaf("u"),
Leaf("x")),
Node(
Leaf("p"),
Leaf("r"))))),
Node(
Node(
Node(
Leaf("n"),
Leaf("s")),
Node(
Leaf("i"),
Leaf("m"))),
Node(
Node(
Leaf("t"),
Leaf("f")),
Leaf(" "))))
We may also produce a plot of the result using Maple's GraphTheory package. This involves converting our tree into a suitable structure. We do not show the necessary code here. Note that the GraphTheory package expects all nodes to be labelled; therefor, we have introduced numbers for the inner nodes. Also note that the picture does not necessarily represent the order of left and right children correctly.
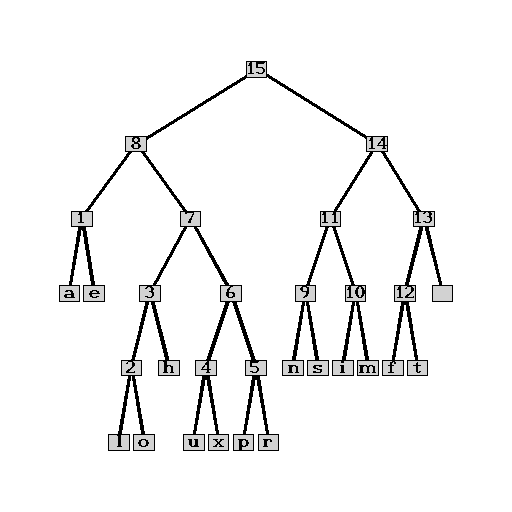
As the picture nicely shows, the more frequent letters a and e are
indeed closer to the root (node 15) than, for instance, the low
frequency letters o and x.
3 Compression
The idea is to base the bit representation of the letters on the paths
from the root of the Huffman tree to the leaf containing the
letter. This will automatically ensure that high frequency letters
have shorter codes since they are closer to the root. We agree that
going to a left child should be represented by a 0 and that going to
right child should be 1. In the example tree, for instance, in order
to reach a, we have to go left three times. Therefor, the code for a
would be 000. Similarly, e is left two times and then right such
that the code is 001.
We use a Maple table to hold the codes for each letter. The easiest
way to navigate a recursive data structure like a tree is to use a
recursive function. Therefor, we define an inner function loop which
descends through the tree and completes the table for us. Its
arguments are tree which is the (sub-) tree that we are currently
working on and sequence which is the path that led to this
particular subtree. If we have reached a leaf, then we just store it
together with its sequence in the table. (Note that cat creates a
single string from the sequence list.) On the other hand, if we have
found a node, then we simply recurse into the left and right subtree,
adapting the sequence as necessary.
HuffmanTreeToTable := proc(tree) local loop, tbl: tbl := table(): loop := proc(tree, sequence) if type(tree, Leaf) then tbl[leafData(tree)] := cat(op(sequence)) else loop(leftSubTree(tree), [op(sequence), 0]): loop(rightSubTree(tree), [op(sequence), 1]) fi end proc: loop(tree, []): return tbl end proc:
Using the table, encoding a string using a given tree is rather easy. We explode the string into its individual characters and look up each character's code in the table. Then we concatenate the results and convert them to a string. (Maple makes them a symbol otherwise.)
HuffmanEncode := proc(input, tree) local tbl, expl, enc: tbl := HuffmanTreeToTable(tree): expl := convert(input, list): enc := map(c -> tbl[c], expl): return convert(cat(op(enc)), string) end proc:
code := HuffmanEncode(wikiExample, tree);
code := "110001011010100111110101001111000100011100101101000101101110010\
000011110100111011110001110101011001101110110110001000111110001\
111001001"
4 Decompression
Decoding a bit sequence like this simply amounts to reconstructing the
paths through the Huffman tree. That is, we start at the root node and
follow the path indicated by the numbers until we reach a leaf. In the
example sequence, we would start by going right, right, left, and left
reaching the leaf for t. We add t to the output and restart the
procedure with the remainder of the bit sequence.
In order to descend through the tree we could have used a recursive inner function again. However, we instead opted for an iterative approach in order to provide an example of how this works. Note that after the exploded string has been exhausted, we still need to add the last letter to the result.
HuffmanDecode := proc(string, tree) local res, expl, subtree: res := "": expl := convert(string, list): subtree := tree: while expl <> [] do if type(subtree, Leaf) then res := cat(res, leafData(subtree)): subtree := tree: else if expl[1] = "0" then subtree := leftSubTree(subtree): else subtree := rightSubTree(subtree): end if: expl := expl[2..] end if end do: res := cat(res, leafData(subtree)): return res end proc:
We can now test our functions on the example from Wikipedia. Note that we do obtain a different tree. However, the length of the encoded string is the same as. Also decoding works as expected.
HuffmanDecode(code, tree);
"this is an example of a huffman tree"
5 Exercises
Exercise. Write a function which converts the bit sequence into numbers (with a width of eight bits each). In order to make this work, the bit sequence must probably be padded with extra bits in the end. This messes up the decoding of course. One way around this is to introduce a special end of input symbol which is appended to each string prior to encoding.
Exercise. The decoding function above requires us to have access to the Huffman tree. Therefor, we need a way to store the tree together with the encoded data. Read up how this works in the Wikipedia article and implement it in Maple.
Exercise. Implement a function for drawing the Huffman trees. You can use the DrawGraph procedure from Maple's GraphTheory library for this. (You will need to translate the tree into the expected data format.)
Exercise. Adding the tree to the encoded string as in the previous exercise means more data and will make the result longer. So, we expect this to pay off only for strings of sufficient size. Take a sample text (like, for instance, the first 500 lines of Shakespeare's "Macbeth") and encode substrings of increasing length. Graph the number of bits of the results and compare them to the standard ASCII encoding (8 bits per character) in order to find the break-even point.